MSA (Memory Sparse Attention) 项目评测报告
🏆 核心结论(先看这里!)
推荐指数:⭐⭐⭐⭐⭐ (5/5)
一句话总结
端到端可训练的稀疏注意力框架,支持100M token超长上下文,性能衰减<9%,超越传统RAG方案。
核心价值
✅ 突破性长上下文 - 从16K扩展到100M token,性能衰减仅<9%
✅ 极致硬件效率 - 2张A800 GPU即可处理100M token推理
✅ 端到端可训练 - 将检索和生成集成到单一可微循环,无需复杂管道
✅ 超越RAG - 在长上下文QA和NIAH基准测试中全面超越最佳RAG方案
📸 产品展示
架构概览
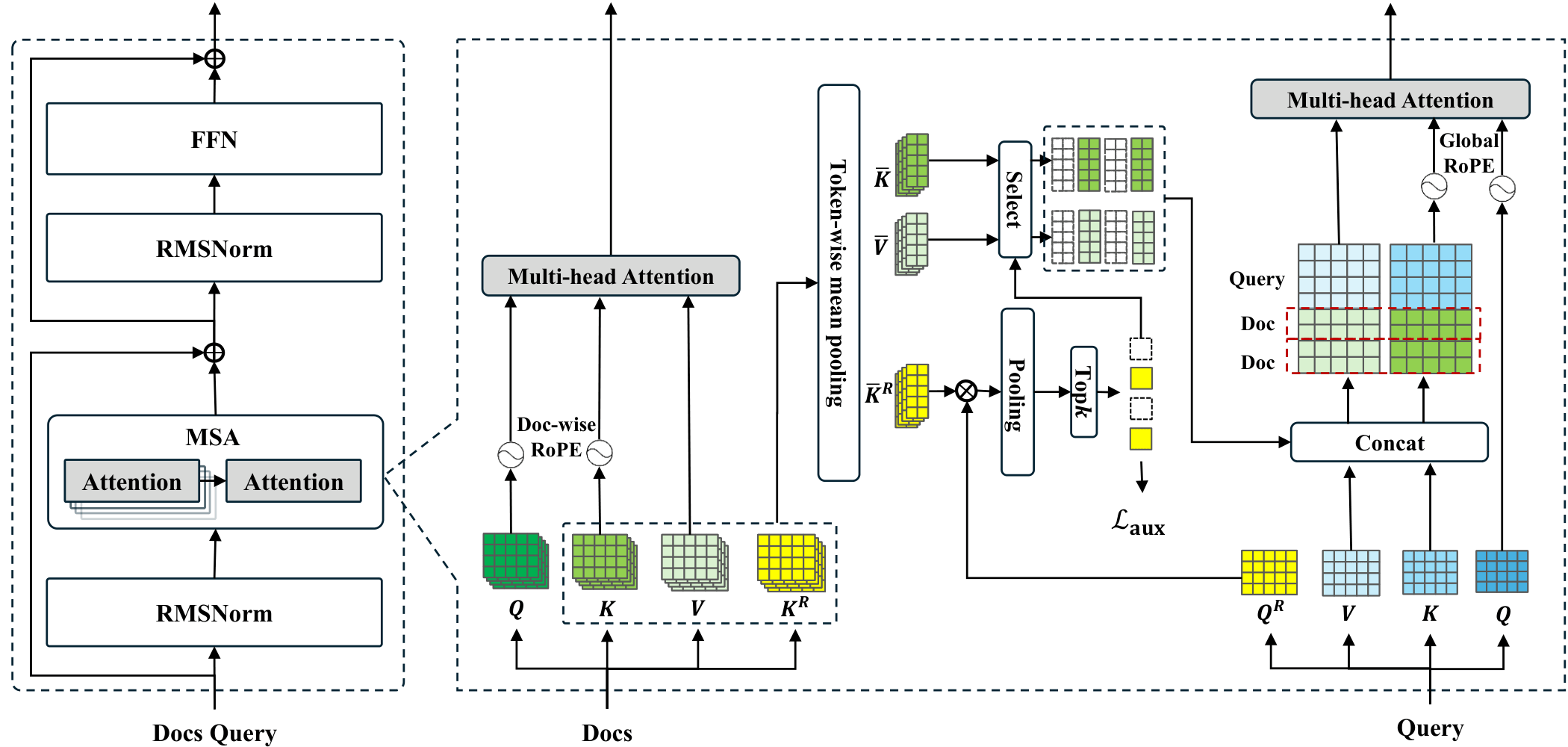
MSA层结构:稀疏注意力 + 文档级RoPE,支持全局和并行位置编码
扩展性能
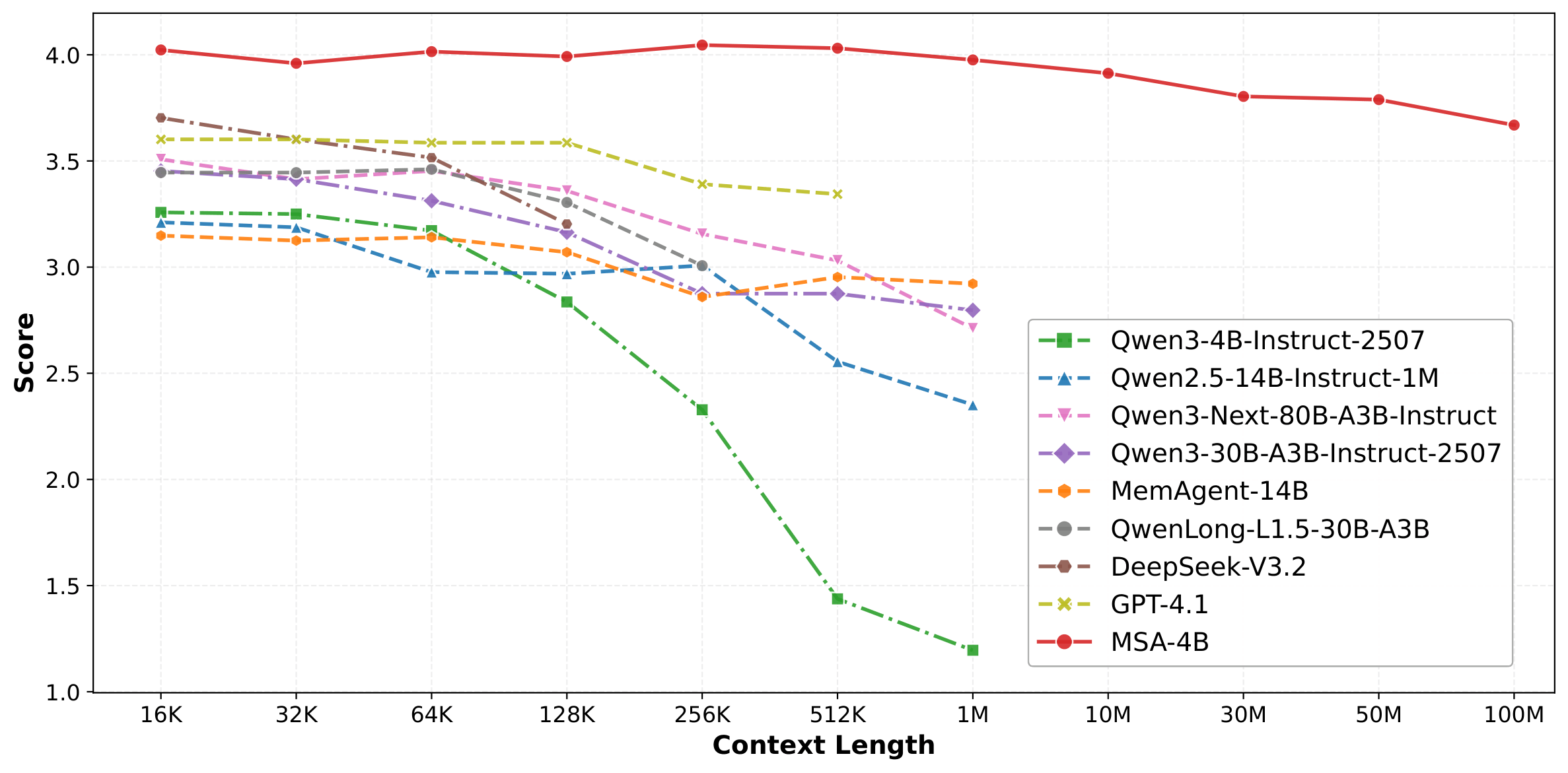
从16K到100M token的扩展曲线,MSA保持<9%性能衰减
推理流程
┌─────────────────────────────────────────────────────────────┐
│ MSA 三阶段推理流程 │
├─────────────────────────────────────────────────────────────┤
│ │
│ 阶段1:全局记忆编码 (离线) │
│ ├── 对语料库进行前向传播 │
│ └── 缓存 chunk-pooled (K̄, V̄, K̄ᵣ) │
│ │
│ 阶段2:在线路由与上下文组装 │
│ ├── 投影查询到 Qᵣ │
│ ├── 与 K̄ᵣ 匹配选择 Top-k │
│ └── 加载选中的 K̄/V̄ 与本地上下文拼接 │
│ │
│ 阶段3:稀疏生成 │
│ └── 在稀疏上下文上自回归生成 │
│ │
└─────────────────────────────────────────────────────────────┘📌 基本信息
| 项目 | 信息 |
|---|---|
| GitHub | EverMind-AI/MSA |
| Stars | 1.1k |
| Forks | 67 |
| License | MIT |
| 主页 | https://evermind.ai |
| 创建时间 | 2025-10-29 |
| 最后更新 | 2026-03-19 |
| 分类 | AI工具 / 研究库 |
🎯 核心特性
功能矩阵
| 模块 | 功能 | 说明 |
|---|---|---|
| Memory-Sparse Attention | 稀疏注意力层 | O(L)复杂度,端到端可训练 |
| Document-wise RoPE | 文档级位置编码 | 支持并行/全局模式,防止位置漂移 |
| KV Cache Compression | KV缓存压缩 | GPU驻留路由键,CPU存储内容K/V |
| Memory Parallel | 内存并行推理 | 分布式评分,按需传输 |
| Memory Interleave | 记忆交织 | 多轮、多跳推理优化 |
核心能力
1. 突破性的长上下文扩展
从16K token扩展到100M token,性能衰减仅<9%,解决了传统LLM有效上下文长度被限制在128K-1M的瓶颈。通过:
- 可扩展稀疏注意力 + 文档级RoPE,实现训练和推理的近线性复杂度
- 文档解耦:推理时允许文档独立处理
- 64K训练 → 100M推理:通过位置编码策略实现超长泛化
2. 极致的硬件效率
在2张A800 GPU上实现100M token推理,通过:
- 分层存储:GPU驻留路由键,CPU存储内容K/V
- 异步获取:选中的内容按需传输
- 分布式评分:K̄ᵣ分片到多个GPU,查询广播 → 本地评分 → 全局归约
3. 端到端可训练框架
将检索和生成集成到单一可微循环:
- 检索即注意力:Top-k选择 + 稀疏注意力融合
- 动态记忆维护:无需外部存储和复杂管道
- 联合优化:检索和生成统一训练
4. 超越传统RAG
在9个长上下文QA数据集上:
- vs 同骨干RAG:平均**+16.0%** 提升
- vs RAG+重排序:平均**+11.5%** 提升
- vs HippoRAG2:平均**+14.8%** 提升
- vs KaLMv2+Qwen3-235B:平均**+7.2%** 提升
🏗️ 技术架构
技术栈
| 层级 | 技术选型 |
|---|---|
| 核心架构 | Memory-Sparse Attention |
| 位置编码 | Document-wise RoPE (并行/全局) |
| 记忆存储 | 分层存储 (GPU路由键 + CPU内容) |
| 并行策略 | Memory Parallel (分布式评分) |
| 训练方案 | 158.95B token连续预训练 + 两阶段SFT |
训练流程
1. 连续预训练 (158.95B tokens)
└── 辅助路由损失
2. 两阶段SFT课程
├── 阶段1: 8K tokens
└── 阶段2: 64K tokens
3. 消融研究表明:
├── 课程扩展: 关键
├── Memory Interleave: +显著提升
├── 连续预训练: 必要
└── 注入原文: 有帮助核心模块
- MSA层:稀疏注意力 + 文档级RoPE,仅在上层应用路由,下层保持独立文档处理
- 路由投影器:计算余弦相似度(先头平均,后token最大),选择Top-k文档
- KV压缩:chunk均值池化,压缩文档潜在状态
- Memory Interleave:自适应交替"生成式检索 → 上下文扩展 → 生成",增强多跳推理
💡 安装与使用
环境要求
- GPU: 2×A800 (或同等算力) 用于100M token推理
- PyTorch (具体版本待公布)
- 其他依赖待代码发布后确认
当前状态
⚠️ 代码和模型即将发布 (Coming Soon)
当前可用资源:
- ✅ 完整论文 (PDF)
- ✅ 实验数据和基准测试结果
- ⏳ 训练代码
- ⏳ 预训练模型
- ⏳ 推理引擎
预期使用方式
# 预期使用示例 (待代码发布)
from msa import MSAModel
# 加载模型
model = MSAModel.from_pretrained("evermind/msa-qwen3-4b")
# 处理超长上下文
context = load_large_corpus() # 支持100M tokens
model.encode_memory(context) # 离线编码
# 查询
answer = model.query(
question="...",
use_memory_interleave=True # 多跳推理
)学习曲线:中等到高(需要理解稀疏注意力和长上下文处理)
🎯 竞争优势对比
竞品对比
| 对比项 | MSA | 传统RAG | 混合线性注意力 | 外部记忆Agent |
|---|---|---|---|---|
| 最大上下文 | 100M | 无限(理论) | 1-10M | 无限(理论) |
| 端到端可训练 | ✅ | ❌ | ✅ | ⚠️ |
| 精度衰减 | <9% | 依赖检索质量 | 显著(≥128K) | 较高 |
| 推理延迟 | 低(稀疏) | 中(RAG管道) | 低 | 高(Agent开销) |
| 硬件需求 | 2×A800 | 1×GPU | 2-4×GPU | 4×GPU+ |
| 多跳推理 | ✅ 原生支持 | ⚠️ 需复杂管道 | ⚠️ 有限 | ✅ |
核心差异化
vs. 传统RAG
- ✅ 端到端可训练,无需手动调参检索器和生成器
- ✅ 动态记忆维护,无需外部存储和复杂管道
- ✅ 在长上下文QA上平均+16.0%提升
- ❌ 需要专门的训练流程
vs. 混合线性注意力模型
- ✅ 从64K训练扩展到100M推理,性能稳定
- ✅ 在≥128K token时精度衰减更小(<9% vs >20%)
- ✅ 显存占用更低(KV缓存压缩)
- ❌ 训练复杂度更高
vs. 外部记忆Agent (RL-MemoryAgent-14B)
- ✅ NIAH测试中绝对精度更高
- ✅ 延迟更低(单次稀疏注意力 vs Agent多轮交互)
- ✅ 无需强化学习训练
- ❌ 灵活性可能略低
🎯 适用场景
✅ 推荐场景
- 超长文档问答 - 法律、医疗、金融等领域的大规模文档检索和问答
- 代码库分析 - 理解和分析百万行级别的代码库
- 知识库问答 - 企业级知识库的智能问答系统
- 多跳推理任务 - 需要跨多个文档推理的复杂问题
- 长对话历史 - 超长对话历史的上下文理解
❌ 不适合场景
- 实时性要求极高 - 虽然推理快,但100M token编码需要时间
- 资源受限环境 - 需要至少2张A800 GPU
- 简单短文本任务 - 对于<16K token的任务,传统方案更简单高效
- 需要完全可解释 - 端到端模型的检索过程不如RAG可解释
✅ 优势
- 突破性技术 - 首次实现从64K训练到100M推理的稳定扩展,性能衰减<9%
- 极致效率 - 仅需2张A800即可处理100M token,远低于同类方案
- 端到端训练 - 无需分别优化检索器和生成器,避免管道误差累积
- 全面超越RAG - 在9个长上下文QA数据集上平均提升7-16%
- NIAH稳定性 - 在1M token时保持94.84%准确率,骨干模型降至24.69%
- 多跳推理 - Memory Interleave机制原生支持复杂推理
- 学术严谨 - 完整的论文、基准测试和消融研究
❌ 不足
- 代码未发布 - 目前仅有论文,训练代码和模型即将发布(Coming Soon)
- 硬件门槛 - 需要2×A800 GPU,对小团队和个人研究者不友好
- 训练成本 - 158.95B token的连续预训练成本高昂
- 技术复杂度高 - 需要深入理解稀疏注意力、RoPE等概念
- 适用范围 - 主要针对长上下文场景,短文本任务可能过度设计
- 生态不完善 - 作为新项目,缺乏社区工具和集成方案
🌐 社区活跃度
| 指标 | 数据 |
|---|---|
| Stars | 1,131 |
| Forks | 67 |
| Open Issues | 2 |
| 创建时间 | 2025-10-29 |
| 最后更新 | 2026-03-19 |
| 维护状态 | 活跃 |
社区生态
- ✅ 完整的学术论文(Zenodo存档,DOI可引用)
- ✅ 详细的实验数据和基准测试
- ✅ 官方主页 https://evermind.ai 提供项目更新
- ⏳ 代码和模型即将发布
- ⏳ 社区工具和集成方案待建立
📊 综合评分
| 维度 | 评分 | 说明 |
|---|---|---|
| 技术创新性 | 9.5/10 | 突破性的长上下文扩展,首次实现64K→100M稳定推理 |
| 易用性 | 6.0/10 | 代码未发布,技术门槛高,学习曲线陡峭 |
| 性能表现 | 9.5/10 | NIAH 94.84%@1M,超越SOTA RAG方案7-16% |
| 功能完整性 | 7.0/10 | 核心功能完善,但代码和模型待发布 |
| 代码质量 | 7.5/10 | 论文质量高,代码待观察 |
| 文档完善度 | 8.5/10 | 论文详细,README清晰,缺乏使用教程 |
| 社区活跃度 | 7.0/10 | 1131 stars,但代码未发布,社区待发展 |
| 可扩展性 | 8.5/10 | 架构设计优秀,支持分层存储和并行推理 |
| 商业价值 | 9.0/10 | 企业级长上下文解决方案,应用场景广泛 |
总体评分:8.1/10.0 ⭐⭐⭐⭐
📌 推荐建议
MSA (Memory Sparse Attention) 是一个突破性的长上下文注意力框架,首次实现了从64K训练到100M推理的稳定扩展,在硬件效率和性能表现上都超越了传统RAG方案。
核心价值:
- 技术突破:解决LLM长上下文的根本瓶颈,实现100M token级别的处理能力
- 成本效益:仅需2×A800即可达到100M token推理,显著降低硬件门槛
- 性能领先:在长上下文QA和NIAH基准测试中全面超越SOTA方案
适用人群:
- AI研究人员和工程师(长上下文、注意力机制方向)
- 企业级应用开发者(知识库、文档问答系统)
- 对超长上下文有刚需的团队
使用建议:
- 关注发布:订阅官方主页,等待代码和模型发布
- 评估需求:确认你的场景确实需要>1M token的上下文
- 准备硬件:确保有足够的GPU资源(至少2×A800)
- 技术储备:提前学习稀疏注意力、RoPE等相关技术
- 小规模验证:代码发布后先在小规模数据验证效果
注意事项:
- 当前代码和模型未发布,无法立即使用
- 硬件要求较高,不适合资源受限环境
- 技术复杂度高,需要团队有较强的AI背景
总结:MSA代表了长上下文LLM的未来方向,技术上具有突破性意义。虽然当前代码未发布,但其论文中的实验结果和技术创新已经展示了巨大潜力。对于有长上下文刚需的团队,这是一个值得密切关注和跟进的项目。
评测时间: 2026-03-21
评测版本: Paper v1.0 (Code Coming Soon)
项目链接: https://github.com/EverMind-AI/MSA
论文链接: MSA Paper